This is a long-form version of a talk I was invited to give at PyDiff (the Cardiff Python meetup) last year The audience was an exciting range of people, from professional software engineers, to mathematicians who’d written their first Python a few weeks prior.
Tools for better Python
There are things that will help you write better Python that are not Python-specific, like practice, good posture, documentation and empathy. These will help you be better at almost everything you do.
There are Python-specific things that will help you write better Python. However you may find them less useful in other areas of life…
Virtualenv
If you’ve a lot of Python experience, you’re probably familiar with virtualenv, but if you’re not already using it, it should make your life substantially easier.
Virtualenv is for creating isolated Python environments.
Are you using root with sudo or something to install your Python packages?
Virtualenv means you don’t have to.
Got a project here that uses Django 1.4 and a project there that uses Django 1.8? Two different virtualenvs, job done.
Under the hood, there’s some fantastic magic and hackery. My favourite bit is that it’s just one Python file; the various skeleton files it deposits in new virtualenvs are stored as zlib-compressed base64-encoded strings.
Tox
Tox is a generic virtualenv management and test command line tool
No need for a manual process of “create a virtualenv, now activate it, now install these things”; tox will do that for you.
For example, here’s a very basic tox.ini file:
[tox]
envlist = py27, py33, py34
[testenv]
deps = -rrequirements-test.txt
commands = nosetestsWith this config I’ve declared three “environments” (represented by different virtualenvs). Thanks to some tox magic, each will have a different version of Python. I’ve specified how to install dependencies, and I’ve said what test commands to run
Now I can run tox (with no arguments) and it’ll create the three different virtualenvs,
install the packages specified in requirements-test.txt into each,
and run nosetests from each.
Or I can run tox -e py27 and only do that for one environment (py27),
e.g. if I was running tests locally by hand and just wanted partial testing in less time.
Prospector
You might be familiar with pylint or pep8.
There’s a lot of static analysis tools out there:
- pylint
- pep8
- pyflakes
- mccabe
- vulture
- dodgy
- pep257
- …and more!
You point them at your code, they’ll give you feedback on quality and conformance. There’s a whole bunch of them, and many people’s opinions differ on what aspects they care about.
Prospector aims to provide sensible defaults. For example most people want to conform to PEP 8. Except PEP 8 mandates a maximum line length of 79 (72 for docstrings). Most common override for pep8? Line length. You can grab each tool individually and tweak as you like, or just grab prospector because life’s too short
Sphinx
Sphinx is a tool that makes it easy to create intelligent and beautiful documentation
You write a bunch of reStructured Text files, it turns them into a beautifully interlinked documentation site. I have strong feels about documentation.
Now, frankly, I find rST hard to write compared to Markdown; all the backticks and the fiddly inline formatting, but what Sphinx is able to layer on top is fantastic interlinking support. For example tables of contents:
.. toctree::
:maxdepth: 2
what_is_laterpay
getting_to_the_office
slack
filing_issues
idonethis
key_user_facing_urlswhich ends up as:

We collect application errors in :doc:`/services/external/sentry`which ends up as:

You can also link to subsections, to figures and diagrams and more, with internal links being checked and validated as part of the build process. Plus you’ve got the usual things like code highlighting, image inclusion etc.
Coverage
Coverage is a tool primarily used for measuring how much of a codebase is exercised by a test suite.
You have some code. You have some tests. How do you know that you’re testing it all, or if you’re not, what bits you’ve missed.
From David R. MacIver’s Empirically Derived Testing Principles (which I strongly agree with):
100% coverage is mandatory
though it’s worth noting that:
100% coverage tells you nothing, but less than 100% coverage tells you something
“100% coverage” doesn’t mean you have good tests, but less than 100% means you definitely have untested code.
It’s particularly important for Python because the following code will quite happily run
(despite the notable absence of cheesecake from Python’s stdlib):
$ cat cheesecake.py
if True:
pass
else:
cheesecake
$ python cheesecake.py
$ echo $?
0Yes that’s a trivial example,
but imagine the case where the if clause is checking the result of a network call,
and cheesecake is your error-handling code.
Most of the time the network call succeeds,
until that one time it doesn’t,
and you find your error-handling code is utter junk and your program dies.
The sooner you find problems, the better. Tests help you do that, especially with good coverage, especially with 100% coverage.
Doctest
The official doctest description:
doctest lets you test your code by running examples embedded in documentation
My description would be: doctest lets you test your documentation by testing example code you embed.
It’s easy for documentation to rot; you change the code, you forget to change the documentation.
For example, here’s a (terrible) implementation of string reversal - takes a string, returns a string. It doesn’t properly handle graphemes and composition etc. but will work well enough. But someone had come along and changed it to return a pair, because, well, reasons.
def reverse(s):
"""
Takes a string and returns it reversed
>>> reverse("hello")
"olleh"
"""
return s, s[::-1]Thanks to doctest:
$ python -m doctest 05-doctest-source.py
**********************************************************************
File "05-doctest-source.py", line 5, in 05-doctest-source.reverse
Failed example:
reverse("hello")
Expected:
"olleh"
Got:
('hello', 'olleh')
**********************************************************************
1 items had failures:
1 of 1 in 05-doctest-source.reverse
***Test Failed*** 1 failures.Hypothesis
Classic testing often looks like a series of anecdotes - David R. MacIver
“Here’s my function, if I give it A do I get B? If I give it C do I get D?” etc. This is limited to “anecdotes you think of”. Hypothesis lets you write tests of the form “given some data like this, does the output satisfy these properties?”
For example, here’s a buggy quicksort:
def quicksort(xs):
if xs == []:
return xs
pivot = xs[0]
left = quicksort([x for x in xs if x < pivot])
right = quicksort([x for x in xs if x > pivot])
return left + [pivot] + rightYou might write some tests and have them pass and believe it works:
>>> quicksort([]) == []
True
>>> quicksort([1]) == [1]
True
>>> quicksort([1,2,3]) == [1,2,3]
True
>>> quicksort([3,2,1]) == [1,2,3]
True
>>> quicksort([3,2,1,4]) == [1,2,3,4]
TrueHowever, a very basic Hypothesis property test…
from hypothesis import given
from hypothesis.strategies import integers, lists
@given(lists(integers()))
def test_length_unchanged(l):
assert len(quicksort(l)) == len(l)
test_length_unchanged()…will quickly show you that’s not the case:
$ python hypothesis-test.py
Falsifying example: test_length_unchanged(l=[0, 0])(The sort doesn’t cover the case when x == pivot!)
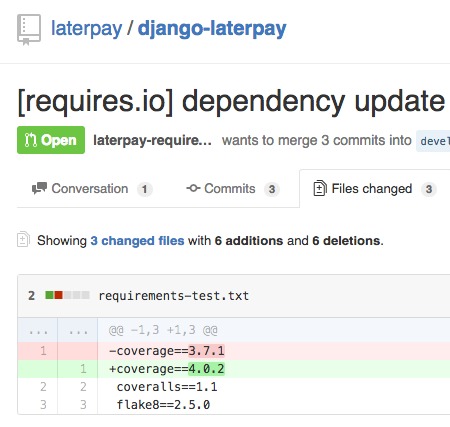
requires.io
Because getting GitHub Pull Requests to update your dependencies is awesome.
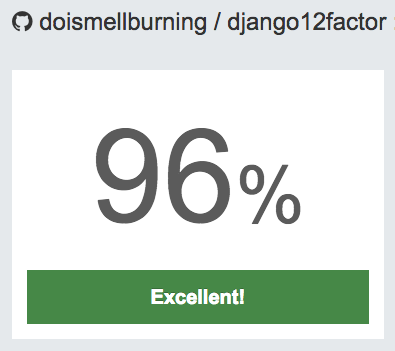
landscape.io
Because Prospector-as-a-Service means you don’t need to run it yourself.
Deliberate Exclusions
Things I wouldn’t recommend. If you use them, I wouldn’t suggest that you stop, but if you’re not, I also wouldn’t necessarily recommend you start.
pdb
pdb is an interactive source code debugger for Python programs.
I’d rather see people diagnose their problems by adding more tests and logging.
IDEs
I’m sure Visual Studio, PyCharm, NetBeans etc. are great,
but if you’re not familiar with one already,
I’d suggest just grabbing a text editor you’re comfortable with.
I’ve seen people do awesome things with MS Word and a cmd.exe window.
If you have an IDE you use and like, great, but while I wouldn’t want to write Java without something like Eclipse or IntelliJ, for Python I’d go more minimal.
Conclusion
I believe these tools are awesome.
I believe they’ll help you write better Python.
I use these for virtually every Python project I build, and suggest you do too.
Recommendations of your own? Let me know!
Why “The Book of Armaments”?
Shoehorning in Monty Python references can be hard sometimes.